
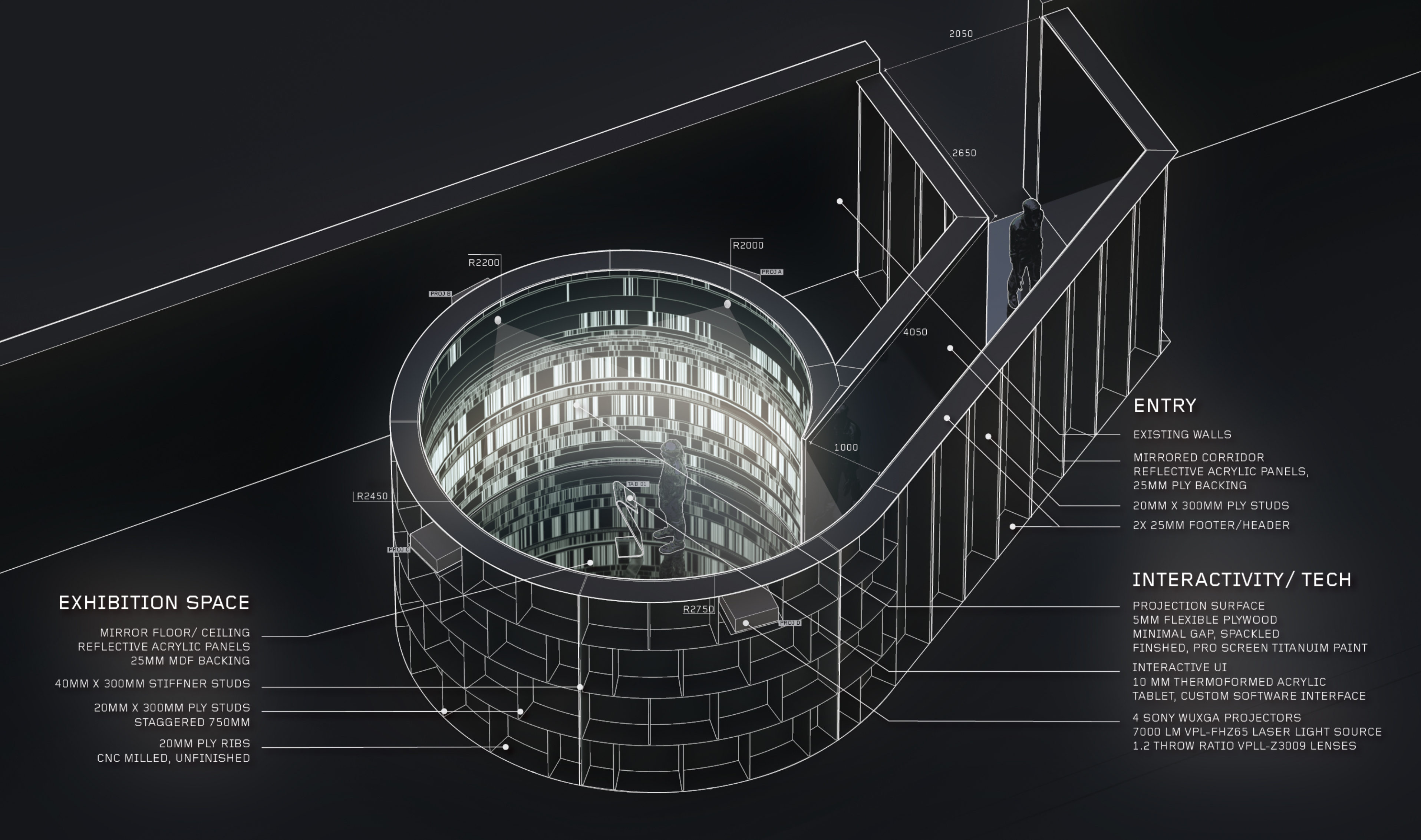
Created by Refik Anadol Studio in collaboration with Google’s Artists and Machine Intelligence program, and installed at the SALT Gatala, Istanbul / Turkey, Archive Dreaming is a 6 meters wide circular installation that employs machine learningalgorithms to search and sort relations among 1,700,000 documents.
Presented as part of The Uses of Art: Final Exhibition with the support of the Culture Programme of the European Union, the installation is user-driven but when idle, the installation “dreams” of unexpected correlations among 1.7 million documents from 17th-20th century Ottoman Bank’s Cultural Archive.. The resulting high-dimensional data and interactions are translated into an architectural immersive space.
The idea was to organize the documents by the conceptual appearance. To do this the team fed each image through a general purpose image recognition network. Rather than using its final classification, the activations of a neural layer or two prior is extracted. This is a 1024 dimensional vector, called an “embedding”, which describes the image contents in terms of high level conceptual features, 1024 features to be precise. They calculated such an embedding for all 1.7M images in the archive. To make this space renderable they needed to reduce the dimensionality from 1024 to two or three. This is where the tSNE algorithm comes in – it tries to arrange the points from the high dimensional space into a 2D plane or a 3D volume while maintaining the close neighbors of each point. This means that images that were close in 1024 dimensional space, by virtue of sharing high-level visual similarity, also end up close to each other in the 2D or 3D projection.


One of the technical challenges of the project was the real-time rendering of 1.7 million images. As a solution, graphics programmer David Gann implemented a dynamic level of detail (DLoD) system in vvvv, a tool well suited for graphic intensive interactive media installations. The modular DirectX 11 library and the general visual programming paradigm of vvvv made it possible to approach and to solve such a complicated problem within a minimum of time. Modern graphics hardware can have quite much memory, but by far not enough to load so many images in a good enough resolution. Another bottleneck is the amount of data that the CPU can upload to the GPU in one operation. Those two limiting factors made it necessary to evaluate two important factors in the beginning of the project: First, what is the maximum resolution for every individual image so that they can load all images in low resolution on the GPU memory. And second, What is the maximum amount of textures that they can upload to the GPU memory at once and how many of those “portions” of textures do they have to prepare for sequential uploading. After these factors where determined, it was possible to pack 32×32 pixel images in a couple of thousand 1024×1024 pixel texture atlases (e.g. a chess board grid containing many small textures). Those textures atlases could then be upload to the GPU in a sequence of texture array loading operations. While the user move through this image cloud, nearby images are loaded in high resolution. This way they could overcome the hardware limitations and enable the visualization of a large amount of images in real-time with a frame rate of 60 frames per second.




↑ TSNE Visualised – Actual and rectified
↑ Adversarial network hallucinating
When the installation is “asleep”, a much more advanced deep learning/generative adversarial network is applied to create hallucinations as if creating an alternative history. A GAN is a type of neural network which can be trained on a large corpus of example data and is then able to generate new examples which look like those in the training set. The GAN method does this by setting up an adversarial game between two competing networks: A discriminator network which tries to learn to distinguish real documents from fake documents and a generator, which tries to generate fake images that fool the discriminator. At first both networks are poor at their respective tasks. But as the discriminator network starts to learn to predict fake from real it keeps the generator on its toes, pushing it to generate harder and harder examples. As the generator gets better the discriminator also has to improve in turn, in order to keep up.




Once trained, the generator can be used to generate new images based on the same statistical rules, creating documents that never existed but look similar to true ones, documents that perhaps could have existed in another version of history.
The final result is a temporary immersive architectural space is created as a canvas with light and data applied as materials. This effort to deconstruct the normal boundaries of the viewing experience of a library and the conventional flat cinema projection screen, into a three dimensional kinetic and architectonic space of an archive visualised with machine learning algorithms.
Project Page | SALT Gatala | Google’s Artists and Machine Intelligence
Credits: from SALT Research including Vasıf Kortun, Meriç Öner, Cem Yıldız, Adem Ayaz, Merve Elveren, Sani, Karamustafa, Ari Algosyan, Dilge Eraslan; from Google AMI including Mike Tyka, Kenric McDowell, Andrea Held, Jac de Haan and finally the Refik Anadol Studio Members & Collaborators including Raman K. Mustafa, Toby Heinemann, Nick Boss, Kian Khiaban, Ho Man Leung, Sebastian Neitsch, David Gann, Kerim Karaoglu and Sebastian Huber.















